When I need a consistent key for a pythohn object I often reach for
hashlib.md5 It works for me and the use cases I have.
diskcache #
Yesterday we talked about setting up a persistant cache with python diskcache. In order to make this really work we need a good way to make consistent cache keys from some sort of python object.
How I setup a sqlite cache in python
hash #
does not work
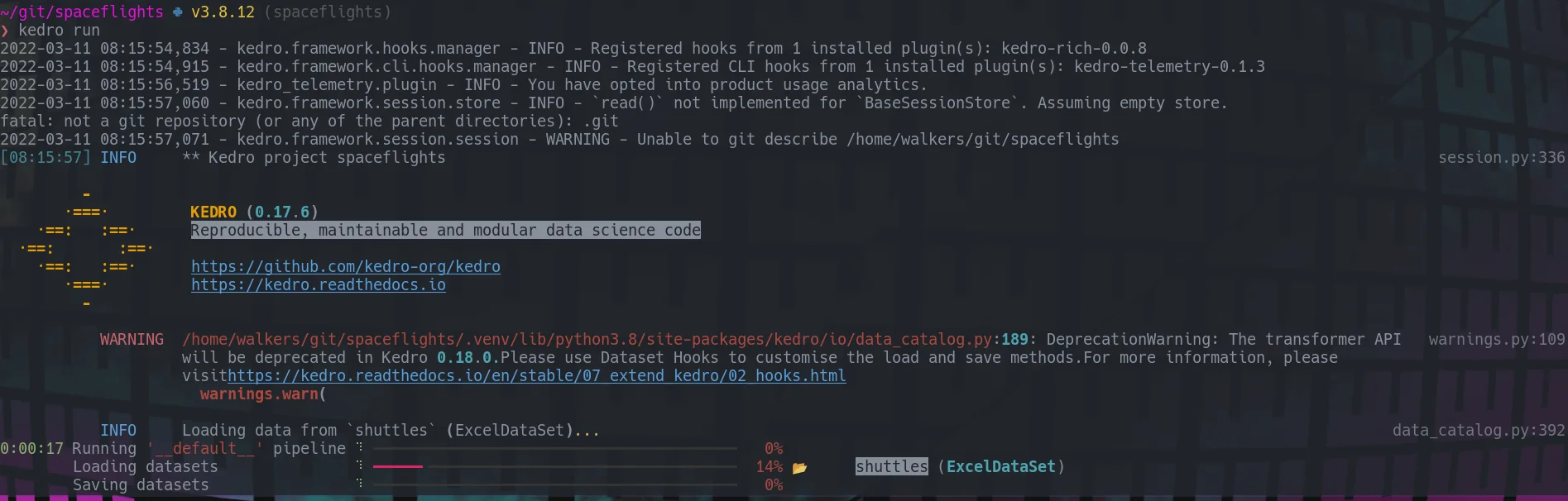
My first thought was to just hash the files, this will give me a unique key for each. This will work, and give you a consistant key for one and only one given python process. If you start a new interpreter you will get different keys.
waylonwalker.com on main [$✘!?] via v5.1.5 v3.8.0 (waylonwalker.com)
❯ ipython
waylonwalker ↪main v3.8.0 ipython
❯ hash("waylonwalker")
-3862245013515310359
waylonwalker ↪main v3.8.0 ipython
❯ hash("waylonwalker")
-3862245013515310359
waylonwalker ↪main v3.8.0 ipython
❯ exit
waylonwalker.com on main [$✘!?] via v5.1.5 v3.8.0 (waylonwalker.com)
❯ ipython
waylonwalker ↪main v3.8.0 ipython
❯ hash("waylonwalker")
-83673051278873734
here is a snapshot of my terminal proving that you can get the same hash in one session, but it changes when you restart ipython.
hashlib.md5 #
Here is a quick couple ipython sessions showing that md5 cache is consistent accross multiple sessions.
waylonwalker.com on main [$✘!?] via v5.1.5 v3.8.0 (waylonwalker.com) on (us-east-1)
❯ ipython
waylonwalker ↪main v3.8.0 ipython
❯ hashlib.md5("waylonwalker")
[PYFLYBY] import hashlib
╭─────────────────────────────── Traceback (most recent call last) ────────────────────────────────╮
│ <ipython-input-1-1537c4473c74>:1 in <module> │
╰──────────────────────────────────────────────────────────────────────────────────────────────────╯
TypeError: Unicode-objects must be encoded before hashing
waylonwalker ↪main v3.8.0 ipython
❯ hashlib.md5("waylonwalker".encode("utf-8"))
<md5 HASH object @ 0x7fe4ba6832d0>
waylonwalker ↪main v3.8.0 ipython
❯ hashlib.md5("waylonwalker".encode("utf-8")).hexdigest()
'1c7c1073ca096ffdb324471770911fe2'
waylonwalker ↪main v3.8.0 ipython
❯ hashlib.md5("waylonwalker".encode("utf-8")).hexdigest()
'1c7c1073ca096ffdb324471770911fe2'
waylonwalker ↪main v3.8.0 ipython
❯ hashlib.md5("waylonwalker".encode("utf-8")).hexdigest()
'1c7c1073ca096ffdb324471770911fe2'
waylonwalker ↪main v3.8.0 ipython
❯ exit
waylonwalker.com on main [$✘!?] via v5.1.5 v3.8.0 (waylonwalker.com) on (us-east-1) took 47s
❯ ipython
waylonwalker ↪main v3.8.0 ipython
❯ hashlib.md5("waylonwalker".encode("utf-8")).hexdigest()
[PYFLYBY] import hashlib
'1c7c1073ca096ffdb324471770911fe2'
key for diskcache #
Since it is consistent we can use it as a cache key for diskcache operations. I setup a little funciton that allows me to pass a bunch of differnt things in to cache. As long as the str method exists and is gives the data that you want to cache key on, this will work.
def make_hash(self, *keys: str) -> str:
str_keys = [str(key) for key in keys]
return hashlib.md5("".join(str_keys).encode("utf-8")).hexdigest()
understanding python *args and **kwargs
If the *args is confusing, I have a full article on
*argsand**kwargs.
See it in action #
Here you can see it in action. Anything passed into the function gets to be part of the key.
waylonwalker ↪main v3.8.0 ipython
❯ def make_hash(self, *keys: str) -> str:
...: str_keys = [str(key) for key in keys]
...: return hashlib.md5("".join(str_keys).encode("utf-8")).hexdigest()
...:
waylonwalker ↪main v3.8.0 ipython
❯ make_hash(1, "one", "1", 1.0)
'73901d019df012a1cdab826ce301217d'
waylonwalker ↪main v3.8.0 ipython
❯ exit
waylonwalker.com on main [$✘!?] via v5.1.5 v3.8.0 (waylonwalker.com) on (us-east-1) took 19m19s
❯
waylonwalker.com on main [$✘!?] via v5.1.5 v3.8.0 (waylonwalker.com) on (us-east-1)
❯ ipython
waylonwalker ↪main v3.8.0 ipython
❯ def make_hash(self, *keys: str) -> str:
...: str_keys = [str(key) for key in keys]
...: return hashlib.md5("".join(str_keys).encode("utf-8")).hexdigest()
[PYFLYBY] import hashlib
waylonwalker ↪main v3.8.0 ipython
❯ make_hash(1, "one", "1", 1.0)
'73901d019df012a1cdab826ce301217d'