I ran into an issue where I was unable to ask localstack for its status. I
would run the command and it would tell me that it didn’t have permission to
read files from my own home directory. Let’s fix it
It dawned on me that the first time I ran localstack was straight docker, not
the python cli. When docker runs it typically runs as root unless the
Dockerfile sets up a user and group for it.
If you have sudo access to the machine you are on you can recursively change
ownership to your user and group. I chose to just give myself ownership of my
whole ~/.cache directory you could choose a deeper directory if you want. I
feel pretty safe giving myself ownership to my own cache directory on my own
machine.
The first example that you can use right now is markata-gh. It will render
repos by GitHub topic and user using the gh cli, which is available in github
actions!
Get it with a pip install
pip install markata-gh
Use it with some jinja in your markdown.
## Markata plugins
It uses the logged in uer by default.
{% gh_repo_list_topic "markata" %}
You can more explicitly grab your username, and a topic.
{% gh_repo_list_topic "waylonwalker", "personal-website" %}
The jinja extension details are for another post, but this is how markata-gh
exposes itslef as a jinja extension.
classGhRepoListTopic(Extension):tags={"gh_repo_list_topic"}def__init__(self,environment):super().__init__(environment)defparse(self,parser):line_number=next(parser.stream).linenotry:args=parser.parse_tuple().itemsexceptAttributeError:raiseAttributeError("Invalid Syntax gh_repo_list_topic expects <username>, or <username>,<topic> both must have the comma")returnnodes.CallBlock(self.call_method("run",args),[],[],"").set_lineno(line_number)defrun(self,username=None,topic=None,caller=None):"get's markdown to inject into post"returnrepo_md(username=username,topic=topic)
In my adventure to learn django, I want to be able to setup REST api’s to feed
into dynamic front end sites. Potentially sites running react under the hood.
I already have the following model from last time I was playing with django. It
will suffice as it is not the focus of what I am learning for now.
Note the name of the model class is singular, this is becuase django will
automatically pluralize it in places like the admin panel, and you would end
up with Itemss.
fromdjango.dbimportmodels# Create your models here.classItem(models.Model):name=models.CharField(max_length=200)created=models.DateTimeField(auto_now_add=True)def__str__(self):returnf"{self.priority}{self.name}"
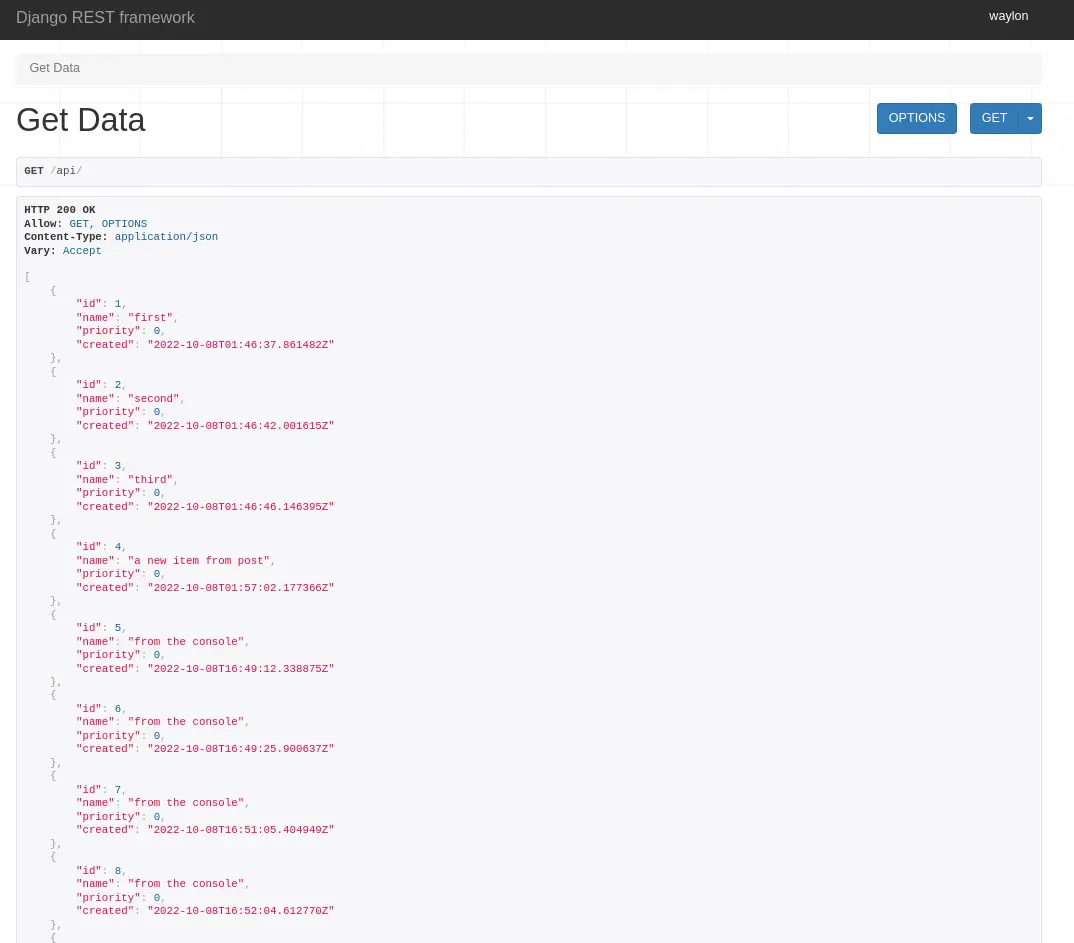
Next I will make some dummy data to be able to return. I popped open ipython
and made a few records.
Next we need to set up a serializer to seriaze and de-serialize data between
our model and json. You can specify each field individually or all of them by
passing in __all__.
Now we need a view leveraging the djangorestframework. The serializer we
just created will be used to serialize all of the rows into a list of objects
that Response can handle.
Note: to return a collection of model objects we need to set many to True
Markata 0.5.0 is now out, and it’s huge. Even though it’s the backend of this
blog I don’t actually have that many posts directly about it. I’ve used it a
bit for blog fuel in generic ways, like talking about pluggy and diskcache, but
very little have I even mentioned it.
Over the last month I made a big push to get 0.5.0 out, which adds a whole
bunch of new configurability to markata.
Before cutting all of my personal projects over to hatch. The first thing I
did was to setup a solid github action,
hatch-actionthat I can resue.
It automatically bumps versions, using pre-releases on all branches other than
main, with special branches for bumping major, minor, patch, dev, alha, beta,
and dev.
To convert the project over to hatch, and get rid of setup.py/setup.cfg, I ran
hatch new --init. This automatically grabs all the metadata for the project
and makes a pyproject.toml that has most of what I need.
hatch new --init
I then manually moved over my isort config, put flake8 config into .flake8,
and dropped setup.cfg.
Part of my hatch-action is to run a before-command, for markata, this runs
all of my linting and testing in one hatch script called lint-test. If this
fails CI will fail and I can read the report in the logs, make a fix and
re-publish.
My typical workflow is to work on features in their own branch where they do
not automatically version or publish, they keep the same version they were
branched off of. Then I do a pr to develop, which will do a minor,dev bump
and publish a pre-relese to pypi.
# starting with version 0.0.0
Feature1 -- │
Feature2 -- ├── dev 0.1.0.dev1,2,3 ── main 0.1.0
Feature3 -- │
I will let several features collect in develop before cutting a full relese
over to main. This gives me time to make sure the solution is what makes the
most sense, I try to use it in a few projects, and generally its edges show,
and another pr is warranted to make the feature useful for more use cases.
After running and using these new releases in a few projects, I am confident
that its ready and release to main.
hatch makes building and publishing pretty straightforward. It’s one command
inside my hatch-action to build and one to publish. On each project that uses
my hatch-action I only need to give it a token that I get from PyPi.
lkwq007 [1] has done a fantastic job with stablediffusion-infinity [2]. Highly recommend taking a look.
Outpainting with Stable Diffusion on an infinite canvas
References:
[1]: https://github.com/lkwq007
[2]: https://github.com/lkwq007/stablediffusion-infinity
Check out toumorokoshi [1] and their project deepmerge [2].
A deep merging tool for Python core data structures
References:
[1]: https://github.com/toumorokoshi
[2]: https://github.com/toumorokoshi/deepmerge
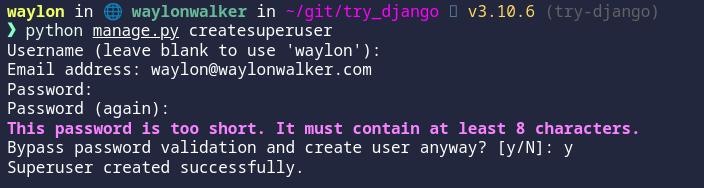
My next step into django made me realize that I do not have access to the admin panel, turns out that I need to create a cuper user first.
My next issue trying to run off of a separate domain was a cross site request
forgery error.
Since this is a valid domain that we are hosting the app from we need to tell
Django that this is safe. We can do this again in the settings.py, but this
time the variable we need is not there out of the box and we need to add it.
You might find these settings helpful as well if you are trying to run your
site on a remote host like aws, digital ocean, linode, or any sort of cloud
providor. I had it running in my home lab while I was out of the house and
ssh’d in over with a chromebook.
I am continuing my journey into django, but today I am not at my workstation. I
am ssh’d in remotely from a chromebook. I am fully outside of my network, so I
can’t access it by localhost, or it’s ip. I do have cloudflared tunnel
installed and dns setup to a localhost.waylonwalker.com.
I found this in settings.py and yolo, it worked first try. I am in from my
remote location, and even have auth taken care of thanks to cloudflare. I am
really hoping to learn how to setup my own auth with django as this is one of
the things that I could really use in my toolbelt.
ALLOWED_HOSTS=['localhost.waylonwalker.com']
I have no experience in django, and in my exploration to become a better python
developer I am dipping my toe into one of the most polished and widely used web
frameworks Django to so that I can better understand it and become a better
python developer.
If you found this at all helpful make sure you check out the django tutorial
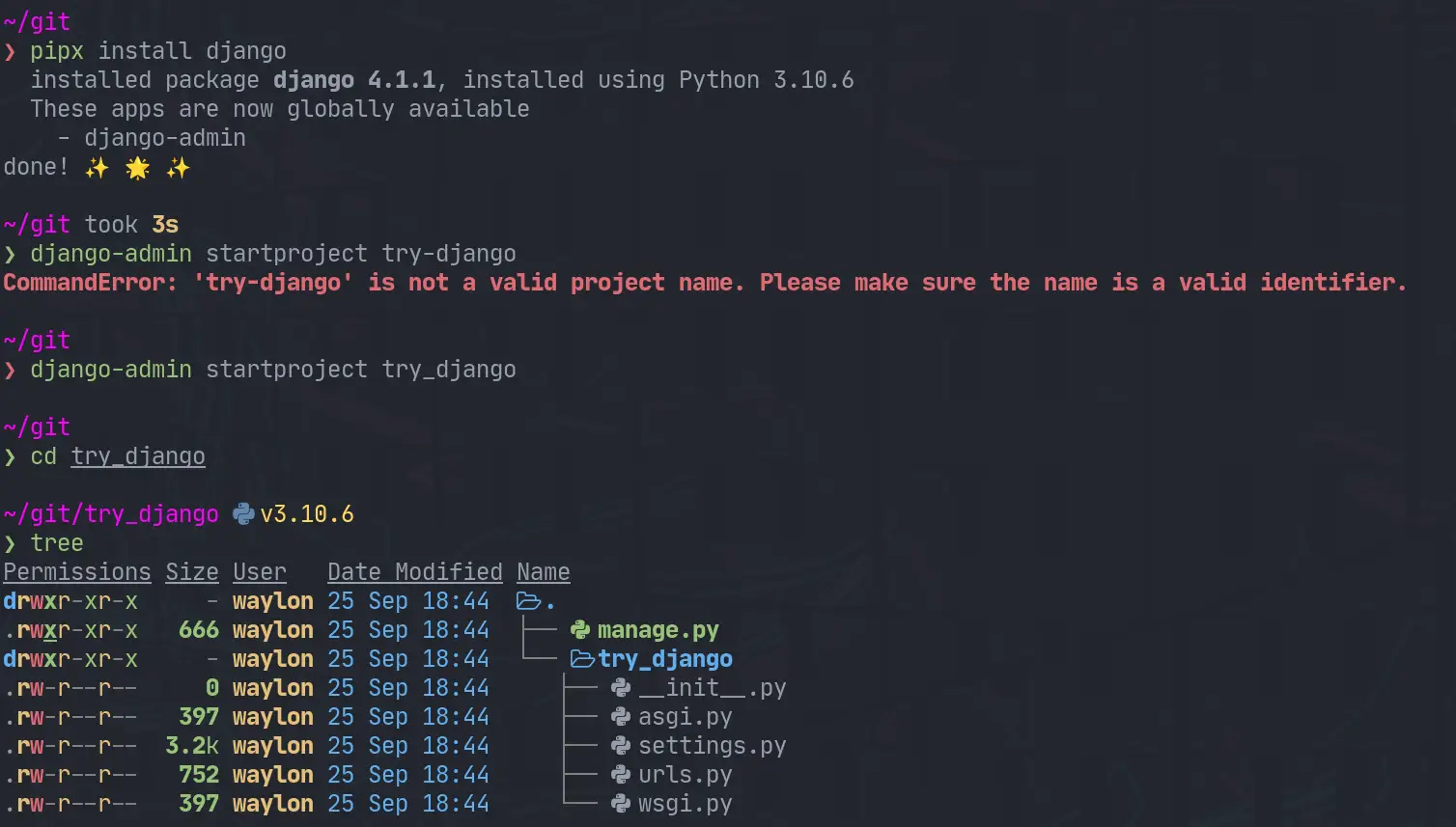
The first thing I need to do is render out a template to start the project.
For this I need the django-admin cli. To get this I am going the route of
pipx it will be installed globally on my system in it’s own virtual
environment that I don’t have to manage. This will be useful only for using
startproject as far as I know.
pipx install django
django-admin startproject try_django
cd try_django
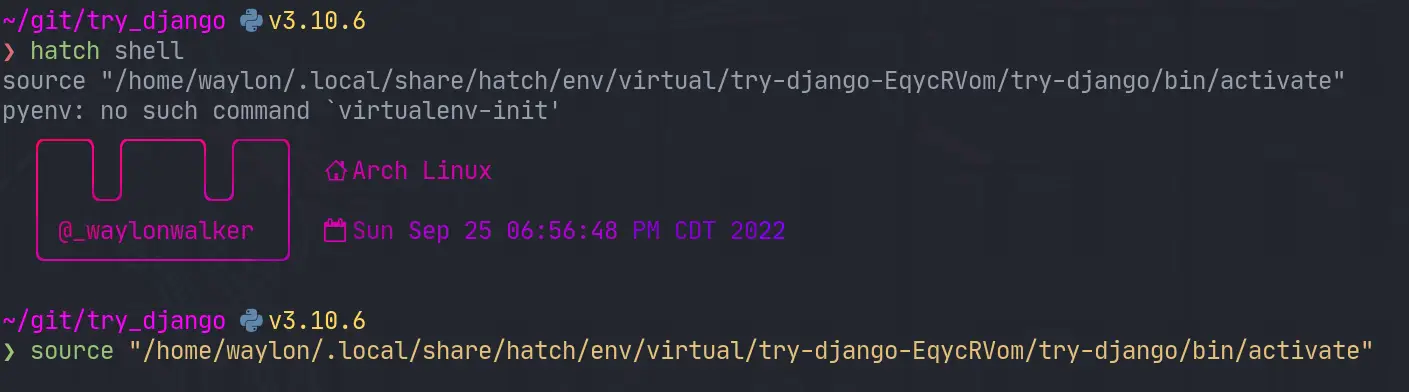
Once I have the project I need a venv for all of django and all of my
dependencies I might need for the project. I have really been diggin hatch
lately, and it has a one line “make a virtual environment and manage it for
me” command.
hatch shell
If hatch is a bit bleeding edge for you, or it has died out by the time you
read this. The ol trusty venv will likely stand the test of time, this is what
I would use for that.
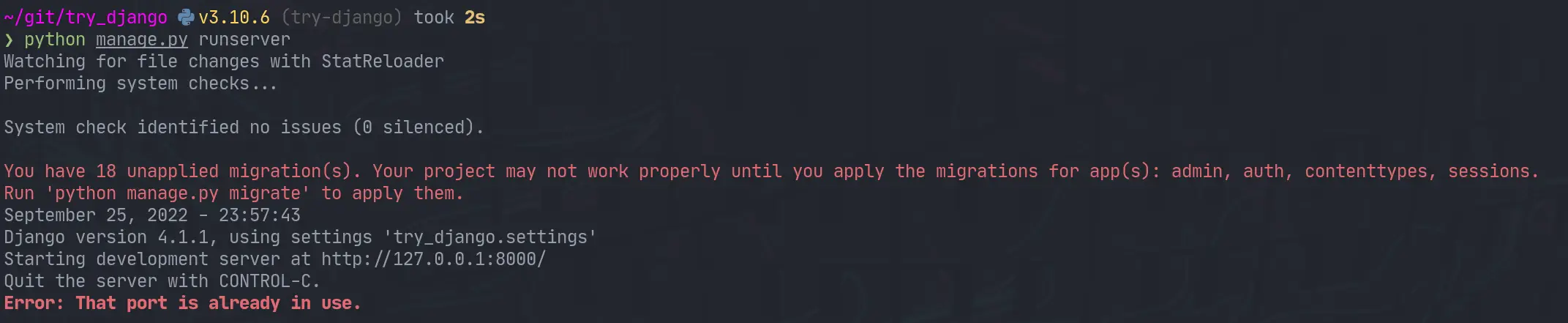
Next up we need to start the webserver to start seeing that development
content. The first thing I did was run it as stated in the tutorial and find
it clashed with a currently running web server port.
python manage.py runserver
I jumped over to that tmux session, killed the process and I was up and running.
I opened up the urls.py to discover that the only configured url was at
/admin. I tried to log in as admin, but was unable to as I have not yet
created a superuser. Next time I play with django that is what I will explore.
While updating my site to use Markata’s new configurable head I ran into some
escaping issues. Things like single quotes would cause jinja to fail as it was
closing quotes that it shouldnt have.
Jinja comes with a handy utility for escaping strings. I definitly tried to
over-complicate this before realizing. You can just pipe your variables into
e to escape them. This has worked pretty flawless at solving some jinja
issues for me.
The issue I ran into was when trying to setup meta tags with the new
configurable head, some of my titles have single quotes in them. This is what
I put in my markata.toml to create some meta tags.
[[markata.head.meta]]name="og:title"content="{{ title }}"
Using my article titles like this ended up causing this syntax error when not
escaped.
After making a complicated system of using html.escape I realized that jinja
included escaping out of the box so I updated my markata.toml to include the
escaping, and it all just worked!.
When I am developing python code I often have a repl open alongside of it
running snippets ofcode as I go. Ipython is my repl of choice, and I hace
tricked it out the best I can and I really like it. The problem I recently
discovered is that I have way overcomplicated it.
So in the past the way I have setup a few extensions for myself is to add
something like this to my ~/.ipython/profile_default/startup directory. It
sets up some things like rich highlighting or in this example automatic
imports. I even went as far as installing some of these in the case I didn’t have them installed.
I missed the fact that some of these tools like pyflyby and rich already
have an ipython extension maintained by the library that just works. It’s less
complicated and more robust to future changes in the library. If anything ever
changes with these I will not have to worry about which version is installed,
the extension will just take care of itself.
The issue that I found with this is that you can end up with a sea of errors
flooding your terminal. Personally I will know immediately if ipython is
working right or not and typically have scriped venv installs so I have
everything I need, so If I don’t have everything it’s probably for a reason and
I don’t need an error message lighting up.
My way around this was to test if the module was importable and if it had a
load_ipython_extension attribute before appending it as an extension.
defactivate_extension(extension):try:mod=importlib.import_module(extension)getattr(mod,"load_ipython_extension")c.InteractiveShellApp.extensions.append(extension)exceptModuleNotFoundError:"extension is not installed"exceptAttributeError:"extension does not have a 'load_ipython_extension' function"extensions=["rich","markata","pyflyby"]forextensioninextensions:activate_extension(extension)
I like pypeaday’s [1] project stable-diffusion-pype-dev [2].
No description available.
References:
[1]: https://github.com/pypeaday
[2]: https://github.com/pypeaday/stable-diffusion-pype-dev
Check out gradio-app [1] and their project gradio [2].
Build and share delightful machine learning apps, all in Python. 🌟 Star to support our work!
References:
[1]: https://github.com/gradio-app
[2]: https://github.com/gradio-app/gradio
Just starred stable-diffusion-webui [1] by AUTOMATIC1111 [2]. It’s an exciting project with a lot to offer.
Stable Diffusion web UI
References:
[1]: https://github.com/AUTOMATIC1111/stable-diffusion-webui
[2]: https://github.com/AUTOMATIC1111
kedro-plugins [1] by kedro-org [2] is a game-changer in its space. Excited to see how it evolves.
First-party plugins maintained by the Kedro team.
References:
[1]: https://github.com/kedro-org/kedro-plugins
[2]: https://github.com/kedro-org
If you’re into interesting projects, don’t miss out on knossos [1], created by modrinth [2].
[Archived] Former repo of the Modrinth frontend
References:
[1]: https://github.com/modrinth/knossos
[2]: https://github.com/modrinth
I like CaffeineMC’s [1] project sodium [2].
A Minecraft mod designed to improve frame rates and reduce micro-stutter
References:
[1]: https://github.com/CaffeineMC
[2]: https://github.com/CaffeineMC/sodium
Just starred markata-todoui [1] by WaylonWalker [2]. It’s an exciting project with a lot to offer.
A todo plugin for markata. It is a tui (text user interface) that runs in the terminal using textual. It gives me a trello-board feel from the terminal. I can create, update, delete, move, and fully manage my todo items from the terminal with it.
References:
[1]: https://github.com/WaylonWalker/markata-todoui
[2]: https://github.com/WaylonWalker
Check out giscus [1] and their project giscus [2].
A comment system powered by GitHub Discussions. :octocat: 💬 💎
References:
[1]: https://github.com/giscus
[2]: https://github.com/giscus/giscus
I recently discovered cmp-nvim-lsp-signature-help [1] by hrsh7th [2], and it’s truly impressive.
cmp-nvim-lsp-signature-help
References:
[1]: https://github.com/hrsh7th/cmp-nvim-lsp-signature-help
[2]: https://github.com/hrsh7th
A long needed feature of markata has been the ability to really configure out
templates with configuration rather. It’s been long that you needed that if
you really want to change the style, meta tags, or anything in the head you
needed to write a plugin or eject out of the template and use your own.
If this does not take you far enough yet, you can still eject out and use your
own template pretty easy. If you are going for a full custom site it’s likely
that this will be the workflow for awhile. Markata should only get better and
make this required less often as it matures.
I recently discovered stable-diffusion-videos [1] by nateraw [2], and it’s truly impressive.
Create 🔥 videos with Stable Diffusion by exploring the latent space and morphing between text prompts
References:
[1]: https://github.com/nateraw/stable-diffusion-videos
[2]: https://github.com/nateraw
gitleaks [1] by gitleaks [2] is a game-changer in its space. Excited to see how it evolves.
Find secrets with Gitleaks 🔑
References:
[1]: https://github.com/gitleaks/gitleaks
[2]: https://github.com/gitleaks
If you’re into interesting projects, don’t miss out on termcharts [1], created by Abdur-rahmaanJ [2].
Terminal charts
References:
[1]: https://github.com/Abdur-rahmaanJ/termcharts
[2]: https://github.com/Abdur-rahmaanJ
Looking for inspiration? markata-slides [1] by WaylonWalker [2].
A slides plugin for markata that allows you to create presentations in markdown from the comfort of your favorite editor. Each new h2 tag (## in markdown) becomes a new slide. This plugin leverages the built-in feeds plugin for navigation, and adds in some hotkeys (j/k) to go the the previous and next slides.
References:
[1]: https://github.com/WaylonWalker/markata-slides
[2]: https://github.com/WaylonWalker
I’m really excited about small-group-notes [1], an amazing project by pypeaday [2]. It’s worth exploring!
Landing zone for small group notes - plan is to make this a nicer website for all things small group related
References:
[1]: https://github.com/pypeaday/small-group-notes
[2]: https://github.com/pypeaday
I’m really excited about meetgor.com [1], an amazing project by Mr-Destructive [2]. It’s worth exploring!
My Personal Blog and Portfolio made with Markata SSG and Python
References:
[1]: https://github.com/Mr-Destructive/meetgor.com
[2]: https://github.com/Mr-Destructive
The work on jinja2-fragments [1] by sponsfreixes [2].
Render Jinja2 template block as HTML [3] page fragments on Python web frameworks.
References:
[1]: https://github.com/sponsfreixes/jinja2-fragments
[2]: https://github.com/sponsfreixes
[3]: /html/
Looking for inspiration? ansible-language-server [1] by ansible [2].
🚧 Ansible Language Server codebase is now included in vscode-ansible repository
References:
[1]: https://github.com/ansible/ansible-language-server
[2]: https://github.com/ansible
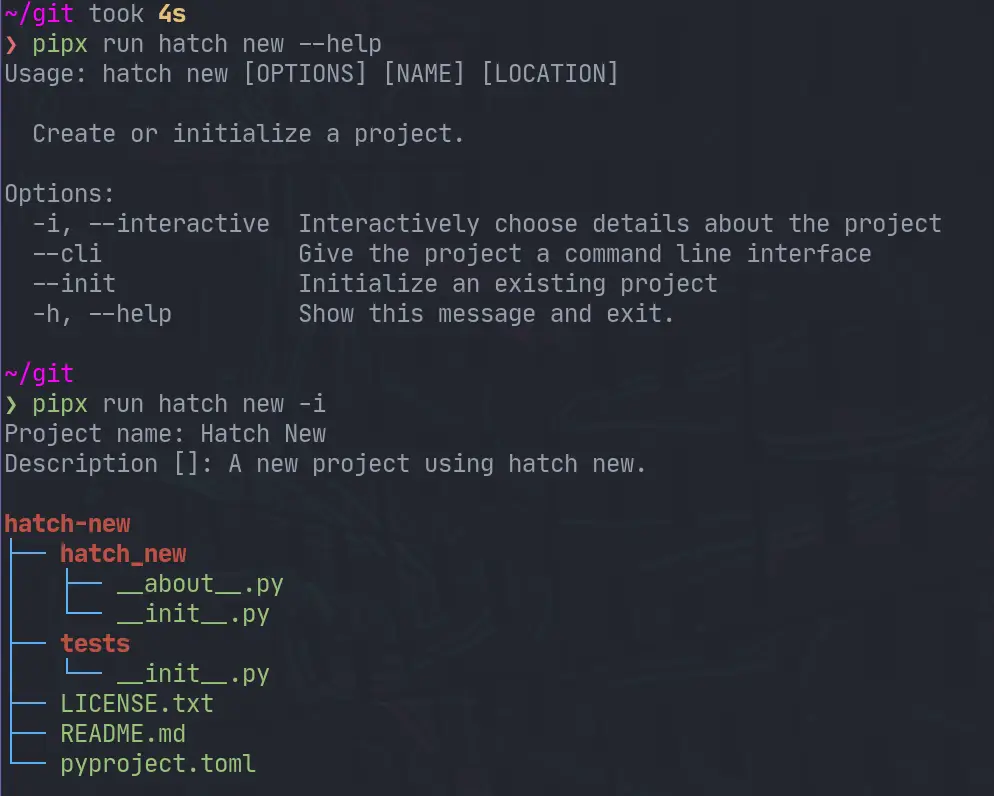
I’m really getting into using hatch as my go to build system, and I am really
liking it so far. I am slowly finding new things that just work really well.
hatch new is one of those things that I didn’t realize I needed until I had
it.
creating new versions created by myself with stable diffusion
❯ pipx run hatch new --help
Usage: hatch new [OPTIONS] [NAME] [LOCATION]
Create or initialize a project.
Options:
-i, --interactive Interactively choose details about the project
--cli Give the project a command line interface
--init Initialize an existing project
-h, --help Show this message and exit.
Note! I am running all of these commands with pipx. I like to use pipx for
all of my system level cli applications. To emphasis this point in the
article I am going to use pipx run hatch, but you can pipx install hatch
then just run hatch from there.
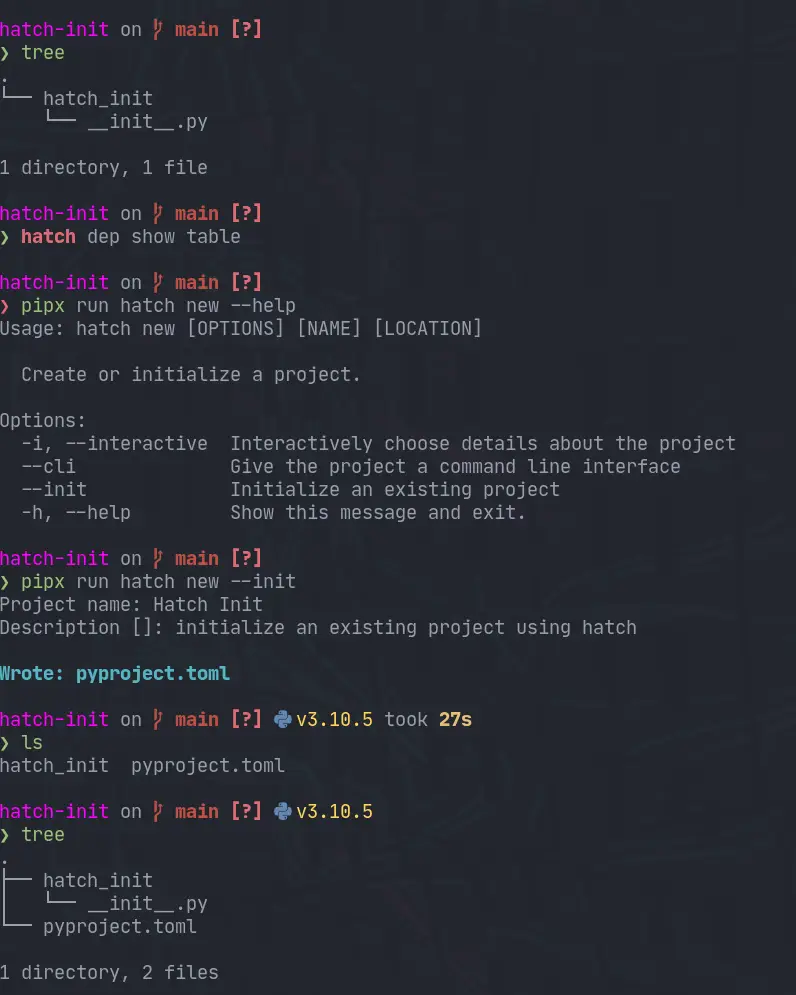
hatch new has an --init flag in order to initialize a new hatch
pyproject.toml in an existing project. This feels like it would be useful if
you are converting a project to hatch, or if like me you sometimes start making
something before you realize it’s something that you want to package. Honestly
this doesn’t happen too much anymore I package most things, and I hope hatch new completely breaks this habbit of mine.
I’ll dive more into environments and the run command later, but we can run the
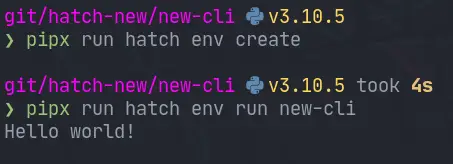
cli pretty damn quick with two commands. In under 5s I was able to run this cli
that it created. This is a pretty incredible startup time.
Hatch has an amazing versioning cli for python packages that just works. It
takes very little config to get going and you can start bumping versions
without worry.
creating new versions created by myself with stable diffusion
The main hero of this post is the pyproject.toml. This is what defines all
of our PEP 517 style project setup.
[project]name="pkg"description="Show how to version packages with hatch"readme="README.md"dynamic=["version",][build-system]requires=["hatchling>=1.4.1",]build-backend="hatchling.build"[tool.hatch.version]path="pkg/__about__.py"
It is possible to set the version number inside the pyproject.toml
statically. This is fine if you just want to version your package manually,
and not through the hatch cli.
[project]name="pkg"version="0.0.0"# ...
Statically versioning in pyproject.toml will not work with hatch version
Cannot set version when it is statically defined by the `project.version` field
Setting the project verion dynamically can be done by changing up the following
to your pyproject.toml. Hatch only accepts a path to store your version. If
you need to reference it elsewhere in your project you can grab it from the
package metadata for that file. I would not put anything else that could
possibly clash with the version, as you might accidently change both things.
If you really need to set it in more places use a package like bump2version.
The hatch project itself uses a
about.py
to store it’s version. It’s sole content is a single __version__ variable. I
don’t have any personal issues with this so I am going to be following this in
my projects that use hatch.
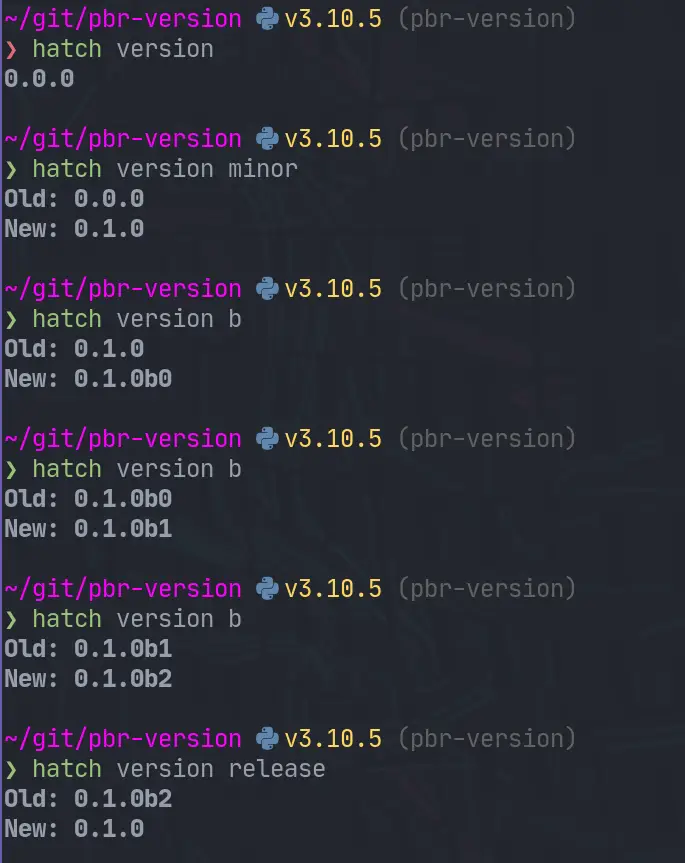
Hatch has a pretty intuitive versioning api. hatch version gives you the
version. If you pass in a version like hatch version "0.0.1" it will set it
to that version as long as it is in the future, otherwise it will error.
# print the current versionhatch version
# set the version to 0.0.1hatch version "0.0.1"
# minor bumphatch version minor
# beta pre-release bump# If published to pypi this can be installed with the --pre flag to piphatch version b
# bump minor and betahatch version minor,b
# release all of the --pre-release flags such as alpha beta rchatch release
In my github actions flow I will be utilizing this to automate my versions. In
my side projects I use the develop branch to release –pre releases. I have
all of my own dependent projets running on these –pre releases, this allows me
to cut myself in my own projects before anyone else. Then on main I
automatically release this beta version.
Here is what the ci/cd for markata looks like. There might be a better
workflow strategy, but I use a single github actions workflow and cut branches
to release –pre releases and full release. These steps will bump, tag,
commit, and deploy for me.
- name:automatically pre-release develop branchif:github.ref == 'refs/heads/develop'run:| git config --global user.name 'autobump'
git config --global user.email '[email protected]'
VERSION=`hatch version`
# if current version is not already beta then bump minor and beta
[ -z "${b##*`hatch version`*}" ] && hatch version b || hatch version minor,b
NEW_VERSION=`hatch version`
git add markta/__about__.py
git commit -m "Bump version: $VERSION → $NEW_VERSION"
git tag $VERSION
git push
git push --tags- name:automatically release main branchif:github.ref == 'refs/heads/main'run:| git config --global user.name 'autobump'
git config --global user.email '[email protected]'
VERSION=`hatch version`
hatch version release
NEW_VERSION=`hatch version`
git add markta/__about__.py
git commit -m "Bump version: $VERSION → $NEW_VERSION"
git tag $VERSION
git push
git push --tags- name:buildrun:| python -m build- name:pypi-publishif:github.ref == 'refs/heads/develop' || github.ref == 'refs/heads/main'uses:pypa/[email protected]with:password:${{ secrets.pypi_password }}
I am setting up a github custom action
waylonwalker/hatch-version-action
that will lint, test, bump, and publish for me in one step. More on that in
the future.
Just starred cloak.nvim [1] by laytan [2]. It’s an exciting project with a lot to offer.
Cloak allows you to overlay *’s over defined patterns in defined files.
References:
[1]: https://github.com/laytan/cloak.nvim
[2]: https://github.com/laytan
Markata is a great python framework that allows you to go from markdown to a
full website very quickly. You can get up and running with nothing more than
Markdown. It is also built on a full plugin architecture, so if there is extra
functionality that you want to add, you can create a plugin to make it behave
like you want.
The talk is live on YouTube. Make sure you check out the other videos from the
conference. There were quite a few quality talks that deserve a watch as well.
Markata # [1]
I open sourced the static site framework that I use to build
my-blog [2] among other side projects. It’s a plugins
all the way down static site generator, that makes me happy to use.
{% gh_repo_list_topic “waylonwalker”, “markata” %}
Repos used to build this blog # [3]
my-blog [2] is built on a number of small repos. I
set it up this way so that creating content is fast and easy to do. I don’t
have to worry about carrying around large images with my lightweight text
files just to make some posts.
{% gh_repo_list_topic “waylonwalker”, “personal-website” %}
Kedro # [4]
I am a heavy user of the kedro [5] framework, and a big
advocate for using some sort of DAG framework for your data pipelines. kedro
is built all in python which makes it easy for a python dev like me to extend,
run, maintain, and deploy.
{% gh_repo_list_topic “waylonwalker”, “kedro” %}
Neovim Plugins # [6]
I use vim for all of my text editing needs. It brings me joy to make any part
of it just a...
I spoke at python webconf in March 2022 about how I deploy this blog on a
continuous basis.
Building this blog has brought me a lot of benefits. I have
a set of custom curated notes to help describe a problem and how to solve it to
me. At theis point it’s not uncommon to google an Issue I am having and
finding my own blog with exactly the solution I need at the top.
I also bump into people from time to time that recognize me from the blog, its
a nice conversation starter, and street cred.
The talk recently released on Youtube, you can watch it without having a ticket
to the conference for free. There were a bunch of other talks that you should
check out too!
rofi-network-manager [1] by P3rf [2] is a game-changer in its space. Excited to see how it evolves.
A manager for network connections using bash, rofi, nmcli,qrencode.
References:
[1]: https://github.com/P3rf/rofi-network-manager
[2]: https://github.com/P3rf
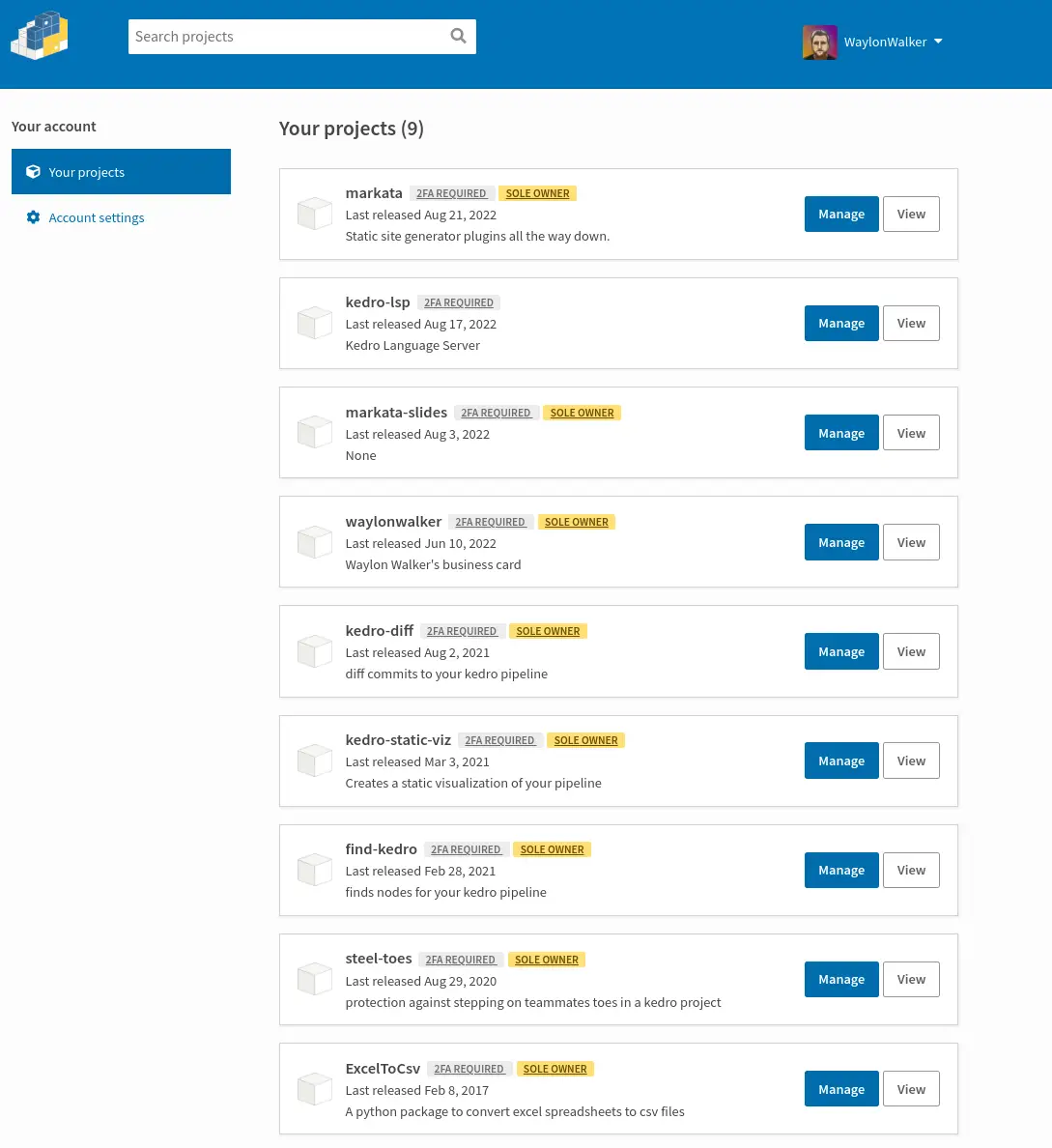
I got all the pypi packages that I own behind 2 factor authentication. 💪
Recently this really made it’s rounds in the python news since pypi was
requiring critical package maintainers to have 2FA on and even offering them
hardware tokens to help them turn this on.
I feel like this caused a bit of confusion as turning on 2FA does not mean that
you need to do anything different to deploy a package, and it DOES NOT
require a hardware token. You can continue using your favorite 2FA app.
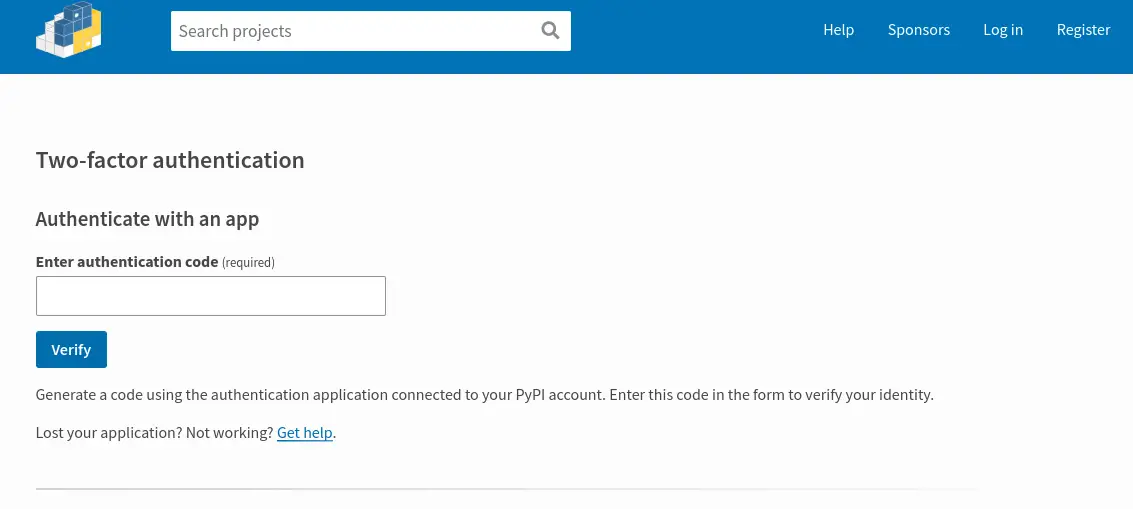
You might wonder what this means for my projects. It means that to edit any
sensitive content such as pull a new api token, add/remove maintainers, or
deleting a release I need to use a TOPT (time based one time password)
application such as Google Authenticator, Microsoft Authenticator, Authy, or
FreeOTP.
This has very little change to my overall workflow as my CI system still
automatically deploys for me with the same api token as before.
This is one small thing that maintainers can do to prevent supply chain attacks
on their projects that they put so much work into.
Once I turned on 2FA for my account I could then turn on 2FA requirement for
each project. I am not sure how much safety there is in pypi, it might require
all maintainers to have it turned on before it allows packages to have it
turned on.
Once turned on it requires anyone who maintains the project to have 2FA on to
be able to edit any sensitive content.
After years of listening to talkpython.fm [1] I had the
honor to be part of
episode-337 [2]
to talk about Kedro for maintainable data science.
I was quite nervous to talk on a show that I helped shape my career in such a
profound way. I started my journey towards software engineering near Michaels
first few episodes. His discussions with such great developers over the years
has made an huge impact on my skill. It has always given me great advice and
topics to go deeper on.
During the episode I tried my best to let Yetu and Ivan take the spotlight as
the maintainer and chime in with my experience as a user of kedro.
Video Version # [3]
https://youtu.be/WTcjvwkXoY0
Michael made the call available on youtube as well as the audio only
podcast [2]
References:
[1]: https://talkpython.fm/
[2]: https://talkpython.fm/episodes/show/337/kedro-for-maintainable-data-science
[3]: #video-version
Check out squidfunk [1] and their project mkdocs-material [2].
Documentation that simply works
References:
[1]: https://github.com/squidfunk
[2]: https://github.com/squidfunk/mkdocs-material
I just love how some features of vim are so discoverable and memorable once you
really start to grasp it. Sorting and uniqing your files or ranges is one of
those examples for me.
" sort the file:sort" sort the file only keeping unique lines:sortu" sort a range:'<,'>sort" sort a range only keeping unique lines:'<,'>sortu
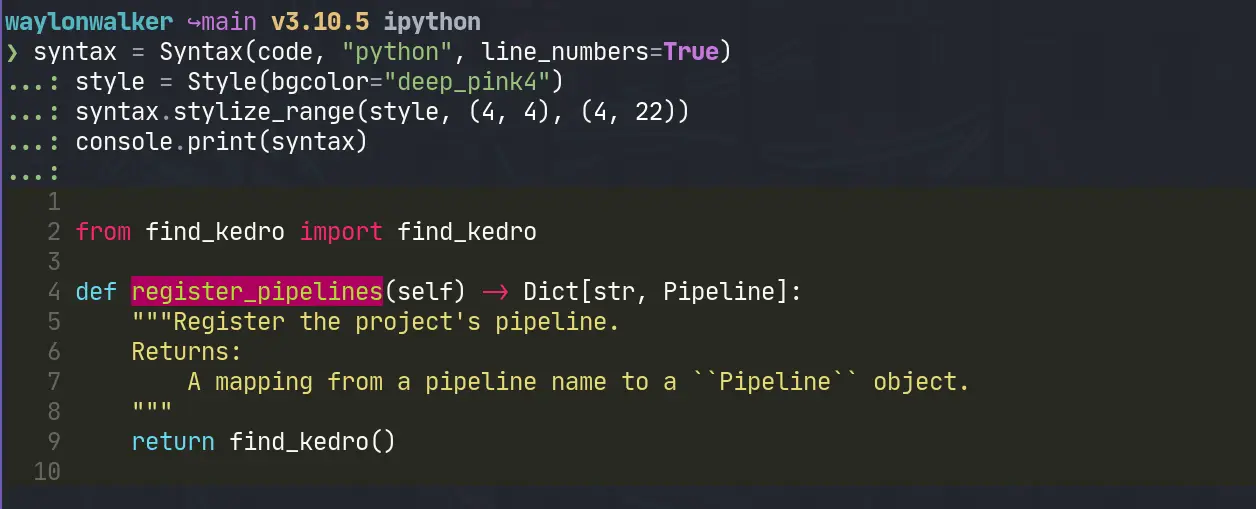
I recently used this to dedupe my autogenerated links section for
rich-syntax-range-style.
More often I am using it to sort and uniqify objects like arrays and lists.
Today I’ve been playing with
py-tree-sitter a bit and I
wanted to highlight match ranges, but was unable to figure out how to do it
with rich, so I reached out to
@textualizeio for help.
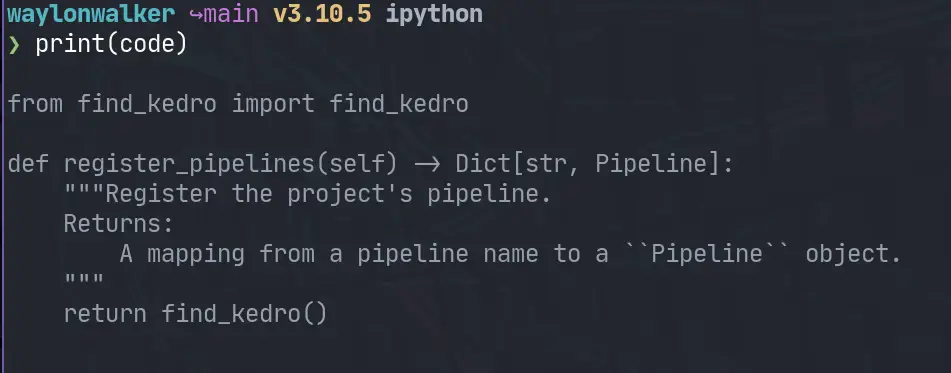
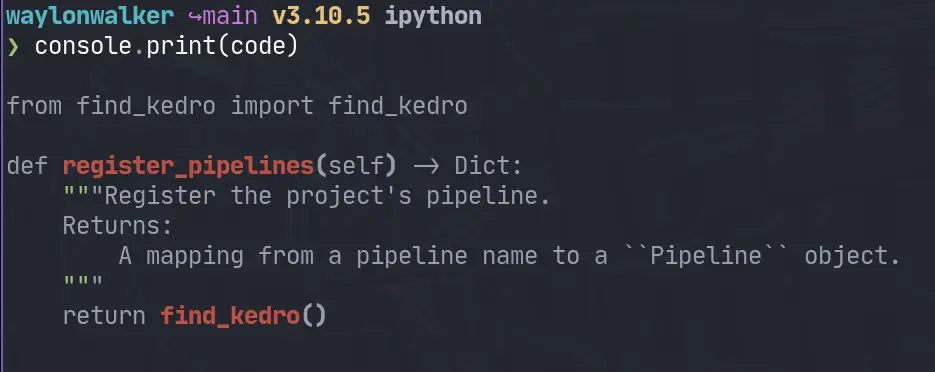
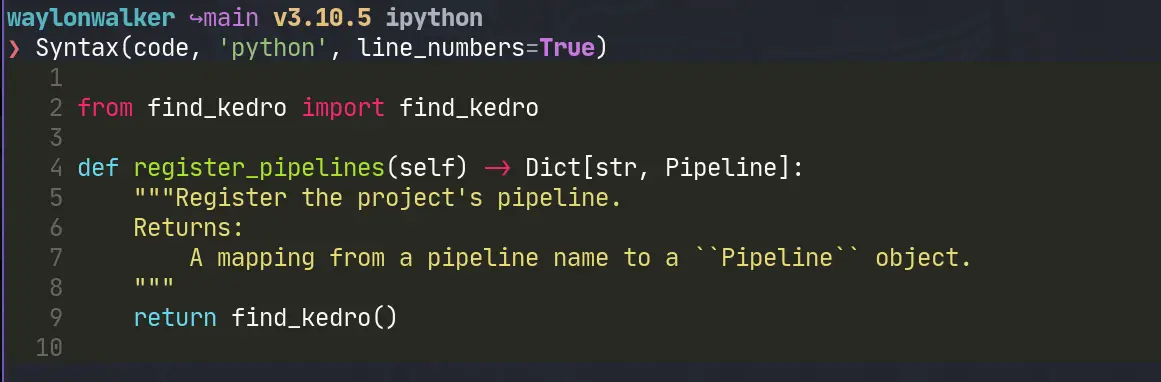
Now we need some code to highlight. I am going to rip my register_pipeline
from another post.
code='''
from find_kedro import find_kedro
def register_pipelines(self) -> Dict[str, Pipeline]:
"""Register the project's pipeline.
Returns:
A mapping from a pipeline name to a ``Pipeline`` object.
"""
return find_kedro()
'''
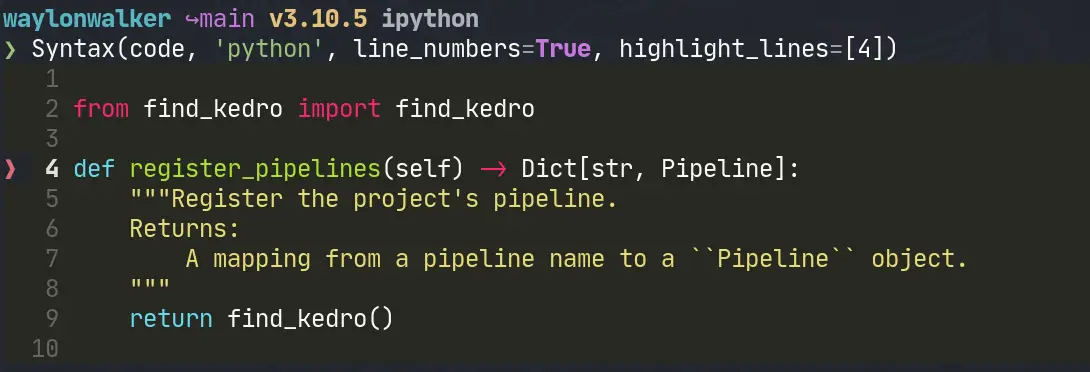
Now we can start highlighting lines right when we initialize our Syntax
instance. It looks ok. It’s not super visible, but more importantly its not
granular enough. I want to highlight specific ranges like the word
register_pipelines.
I needed to delete all build pipeline steps that were named upload docs. I
currently have about 60 projects running from the same template all running
very similar builds. In the past I’ve scripted out migrations for large
changes like this, they involved writing a python script that would load the
yaml file into a dictionary, find the corresponding steps make the change and
write it back out.
Today’s job was much simplar, just delete the step, were all steps are
surrounded by newlines. My first thought was to just open all files in vim and
run dap. I just needed to get these files:positions into my quickfix. My
issue is that all the builds reside within hidden directories by convention.
After searching through all the projects it was clear that all the steps were
in their own paragraph, though I was not 100% confident enough to completely
automate it, and the word upload docs was in the paragraph.
Templates are amazing, and tools like cookiecutter and copier are essential in
my workflow, but those templates change over time. Some things are a constant,
and others like this one are an ever evolving beast until they are tamed into
something the team is happy with.
I know all the files that I care to search for are called build.yml, and they
are in a hidden directory.
:args `fd -H build.yml`
:vimgrep /upload docs/ ##
Once opened as a buffer by using args, and a handy fd command I can vimgrep
over all the open buffers using ##
Open buffers are represented by ##
Now I can just dap and :cnext my way through the list of changes that I
have, and know that I hit every one of them when I am at the end of my list.
And can double check this in about 10s by scrolling back through the quickfix
list.
You’re not a true vim enthusiast until you have spent 10 minutes writing a blog
post about how vim saved you 5 minutes. Check out all the other times this has
happened to me in the vim tag.
a sprinter edging out his opponent by Dall-e
It’s about time to release Markata 0.3.0. I’ve had 8 pre-releases since the
last release, but more importantly it has about 3 months of updates. Many of
which are just cleaning up bad practices that were showing up as hot spots on
my pyinstrument reports
Markata started off partly as a python developer frustrated with using nodejs
for everything, and a desire to learn how to make frameworks in pluggy. Little
did I know how flexible pluggy would make it. It started out just as my blog
generator, but has turned into quite a bit more.
Over time this side project has grown some warts and some of them were now
becoming a big enough issue it was time to cut them out.
I like to use my tils articles for examples and tests like this as there are
enough articles for a good test, but they are pretty short and quick to render.
mkdir ~/git/tils/tils
cp ~/git/waylonwalker.com/pages/til/ ~/tils/tils -r
cd ~/git/tils/tils
python3 -m venv .venv --prompt $(basename $PWD)# --pre installs pre-releases that include a b in their version namepip install markata --pre
markata clean
markata build
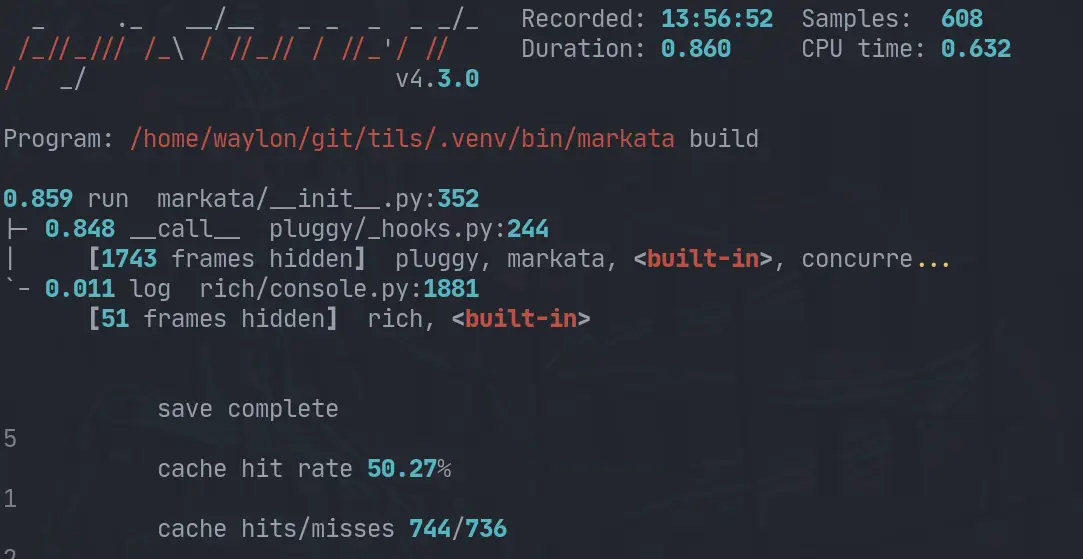
These measurements were taken with pyinstrument mostly out of convenience since
there is already a pyinstrument hook built in, but also because I like
pyinstrument.
Here is the pyinstrument report from the last run.
Most of these changes revolve in how the lifecycle is ran. It was trying to be
extra cautious and run previous steps for you if it thought it might be
needes, in reality it was rerunning a few steps multiple times no matter what.
The other thing I turned off by default, but can be opted into, is
beautifulasoup’s prettify. That was one of the slower steps ran on my site.
It should be out by the time you see this, I wanted to compare the changes I
had made and make sure that it was still making forward progress and thought I
would share the results.
Check out stable-diffusion [1] by CompVis [2]. It’s a well-crafted project with great potential.
A latent text-to-image diffusion model
References:
[1]: https://github.com/CompVis/stable-diffusion
[2]: https://github.com/CompVis
People exceptionally talented in the Deliberative theme are best described by
the serious care they take in making decisions or choices. They anticipate
obstacles.
I am risk-adverse. I want everything well thought out and calculated before I
make any sort of change. I have never gambled in my life and just the thought
of it makes me anxious.
One of the biggest ways that I utilize this skill is automation. I am all
about automating things, not just because I don’t want to do the manual work,
but I am not sure when I am going to need to do something again.
Check out archlinux [1] and their project aur [2].
⚠️⚠️Experimental aur [3].git [4] mirror⚠️⚠️ (read-only mirror)
References:
[1]: https://github.com/archlinux
[2]: https://github.com/archlinux/aur
[3]: /aur/
[4]: /glossary/git/
A common meta thing that I need in python is to find the version of a package.
Most of the time I reach for package_name.__version__, but that does not
always work.
In searching the internet for an answer nearly every one of them pointed me to
__version__. This works for most projects, but is simply a convention, its
not required. Not all projects implement a __version__, but most do. I’ve
never seen it lie to me, but there is nothing stopping someone from shipping
mismatched versions.
While its not required its super handy and easy for anyone to remember off the
top of their head. It makes it easy to start debugging differences between
what you have vs what you see somewhere else. You can do this by dropping a
__version__ variable inside your __init__.py file.
Your next option is to reach into the package metadata of the package that you
are interested in, and this has changed over time as highlighted in the stack
overflow post.
for Python >= 3.8:
from importlib.metadata import version
version('markata')
# `0.3.0.b4`
I only really use python >= 3.8 these days, but if you need to implement it for
an older version check out the stack overflow post.
Well we have a cli tool that wraps around piptools and we wanted to include the
version of piptools in the comments that it produces dynamically. This is why
I wanted to dynamically grab the version inside python without shelling out to
pip show. Now along with the version of our internal tool you will get the
version of piptools even though piptools does not ship a __version__
variable.
In the end, I am glad I learned that its so easy to use the more accurate
package metadata, but still appreciate packages shipping __version__ for all
of us n00b’s out here.